
A los editores se les dijo que «nunca es demasiado tarde» para comenzar a bloquear los sitios que son rastreados por bots de IA.
Por Charlotte Tobitt
Casi ocho de cada diez de los sitios web de noticias más importantes del Reino Unido y los EE. UU. ahora están bloqueando los bots de entrenamiento de IA .
Esta semana, en Londres, se les dijo a los editores que «nunca es demasiado tarde» para comenzar a bloquear los bots debido a la frecuencia con la que se debe realizar un nuevo rastreo a través de la generación aumentada por recuperación para que las respuestas del chatbot de IA se mantengan actualizadas.
Alrededor del 79% de casi 100 sitios web de noticias principales en el Reino Unido y los EE. UU. están bloqueando al menos un rastreador utilizado para el entrenamiento de IA: GPTBot, ClaudeBot, Anthropic-ai, CCBot, Applebot-Extended y Google-Extended de OpenAI.
Mientras tanto, el 71 % impide que los bots de IA rastreen sus sitios para recuperar información o realizar búsquedas en tiempo real. Estos bots son: ChatGPT-User, Claude-Web, Perplexity-User y OAI-SearchBot.
El último análisis de quién estaba bloqueando qué fue realizado por la plataforma de relaciones públicas digitales Buzzstream, analizando una lista combinada y deduplicada de los 50 sitios web de noticias más importantes de cada uno de los Estados Unidos y el Reino Unido , y compartida con Press Gazette.
Entre los 50 principales editores que bloquearon todos los bots de IA incluidos en el análisis se encuentran: la BBC (tanto sus dominios .co.uk como .com), The New York Times, Daily Mail, The Telegraph, Sky News, AP News, New York Post, Newsweek, NBC News, Wall Street Journal, Metro, Business Insider, ABC News, Buzzfeed, Huffpost y The Hill. Esto significa que el 34 % de los 50 principales bloquearon todos los bots.
Alrededor del 14% de los 50 editores principales tuvieron acceso a los 11 rastreadores de IA analizados: Fox News, The Independent, GB News, Substack, Standard, Drudge Report y Politico.
Sitios web de noticias vs. bots de IA: ¿Quién bloquea qué?
El director de SEO de Telegraph, Harry Clarkson-Bennett, dijo a Buzzstream: “Los editores están bloqueando los bots de IA que usan robots.txt porque casi no hay intercambio de valor.
“Los LLM no están diseñados para enviar tráfico de referencia y los editores (aún) necesitan tráfico para sobrevivir.
“Por eso, la mayoría de nosotros bloqueamos los bots de IA porque estas empresas no están dispuestas a pagar por el contenido con el que se ha entrenado su modelo y su producción es casi completamente interna”.
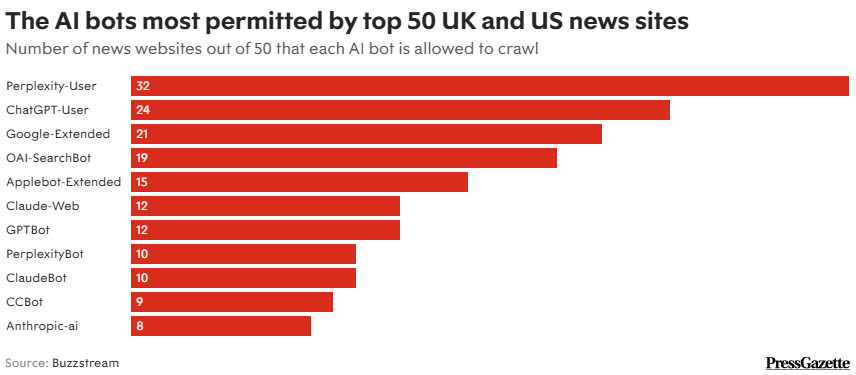
De los 50 sitios web más grandes analizados, Perplexity-User fue el más permitido (con 32 permisos), seguido de ChatGPT-User (24). Ambos son rastreadores de recuperación/búsqueda en vivo que determinan si Perplexity o ChatGPT pueden acceder a un sitio web en tiempo real para responder a las preguntas de los usuarios. Por otro lado, Perplexity-Bot muestra y enlaza sitios web dentro de los resultados de búsqueda de Perplexity.
El menos permitido fue el bot de entrenamiento de Anthropic (ocho), seguido por el bot de archivo web de Common Crawl CCBot (nueve).
En febrero de 2024, el análisis de Press Gazette mostró que 61 de los 106 sitios web de noticias más grandes del Reino Unido y los EE. UU. estaban bloqueando al menos un rastreador de IA , lo que muestra un aumento en los últimos dos años.
Google Extended “permite decir sí a la búsqueda y no al entrenamiento de IA”, dijo la semana pasada Roxanne Carter, gerente senior de asuntos gubernamentales y políticas públicas de Google, al Parlamento del Reino Unido.
Google Extended permite a los editores optar por no permitir que el chatbot de IA Gemini y la plataforma de desarrollo de IA Vertex rastreen su contenido, pero no impide que se acceda a los sitios y se los use en las descripciones generales de IA de Google.
Para evitar esto, los editores tendrían que optar por no ser rastreados por Googlebot, que indexa para búsquedas. Googlebot no se incluyó en el nuevo análisis de Buzzstream, pero optar por no participar se ha descrito como una «decisión poco envidiable».
Buzzstream descubrió que los editores estadounidenses son “mucho más agresivos” al bloquear Google Extended (58%) que los editores del Reino Unido (29%).
Entre los 100 principales sitios de noticias de Estados Unidos y el Reino Unido, los sitios estadounidenses son más estrictos en el entrenamiento de bots (81% de bloqueo) que sus colegas del Reino Unido (77%).
Robots.txt no es una forma infalible de bloquear bots de IA, ya que las empresas de IA pueden ignorar sus directivas o eludirlas de maneras como usar empresas de terceros para extraer contenido.
Los errores tipográficos y las configuraciones incorrectas pueden impedir que los editores bloqueen de manera efectiva
Anthony Katsur, director ejecutivo de IAB Tech Lab, dijo en el evento Techtonic de Interactive Advertising Bureau (IAB) en Londres el miércoles que habían «analizado un gran porcentaje» de comandos de editores a bots de IA y encontraron «que hay muchos errores tipográficos o muchas configuraciones incorrectas de robots.txt, lo que significa que es posible que no se obedezcan, no es que siempre se obedezcan de todos modos».
Katsur recomendó a los editores que bloqueen los bots de IA, incluso si aún no lo han hecho, debido a la generación aumentada por recuperación, lo que significa que los modelos de IA generativos recuperan y hacen referencia a nueva información de la web en tiempo real (en lugar de depender de un rastreo de descubrimiento inicial).
Katsur dijo: «Editores, si no han bloqueado y creen que es demasiado tarde para hacerlo, se equivocan. Nunca es demasiado tarde para bloquear».
“Los LLM volverán y volverán a rastrear el contenido para que la información se mantenga actualizada, relevante y precisa”.
También dijo: «En la historia de la humanidad, nunca se ha creado un mercado donde las cosas se regalen o simplemente se roben. Así que, sin escasez, los mercados no existirían. Así que, editores, si no están bloqueando, es poco probable que se forme algún tipo de mercado de contenido».
Katsur sugirió que los editores deberían “unirse” colectivamente y bloquear los bots “de una vez”, aunque sea solo por 72 horas, “solo para demostrar que hay fuerza entre los editores, grandes y pequeños”.
Dijo que si como resultado los editores se vieran amenazados con una demanda antimonopolio o por colusión, «sería un buen problema porque significaría que todavía estarían en el negocio».
Katsur dijo que el IAB Tech Lab cree que los “días de rastreo” no son “sostenibles para los editores”.
“Tampoco creemos necesariamente que sea sostenible para los LLM… a medida que vemos que la burbuja de la IA estalla, creo que desde una perspectiva fiscal o de financiación, el fácil acceso a la compra continua de GPU [unidades de procesamiento gráfico] para financiar los LLM se verá limitado, por lo tanto, se necesitará una mayor eficiencia en términos de cómo se accede y estructura el contenido para LLM más eficientes”.
El IAB Tech Lab está trabajando en una iniciativa alternativa de Protocolos de Monetización de Contenido (CoMP) que, según Katsur, implicaría un «nuevo conjunto de API de código abierto que permitirían a los LLM acceder a contenido de editores o marcas solo bajo estrictos controles y estructuras, protegiendo así su propiedad intelectual, sus derechos de autor y, nuevamente, también brindando a los LLM un formato bien estructurado para un consumo, uso y precisión más eficientes».
En un grupo de trabajo de CoMP celebrado en octubre, Google, Microsoft y Meta participaron junto con los editores. Sin embargo, Katsur afirmó que «no han tenido ninguna objeción por parte de OpenAI, Anthropic, Perplexity y algunas otras empresas más pequeñas».
Fuente: Press Gazette



