
El CTO de Ank, fintech de Itaú Unibanco, dio una capacitación sobre por qué, para qué y cómo trabajar con datos en un medio de comunicación. Fue parte del programa “Roadmap de transformación digital”, que diseñó la Universidad de San Andrés para los socios de Adepa. Editores y directivos periodísticos de todo el país se llevaron consejos para lograr un procesamiento efectivo de la información de la audiencia, para mejorar la sustentabilidad de sus productos y la generación de nuevos servicios.
Como parte del Programa especial “Roadmap de transformación digital”, diseñado por el área de Management Integral de Negocios Digitales (MIND) de la Universidad de San Andrés para los medios miembros de la Asociación de Entidades Periodísticas Argentinas (Adepa), el speaker invitado para la tercera semana de capacitaciones fue Gustavo Arjones, CTO de Ank, fintech de Itaú Unibanco. Lleva más de 20 años trabajando en Marketing Digital y Tecnología y liderando soluciones en base a Datos, Big Data y Machine Learning.
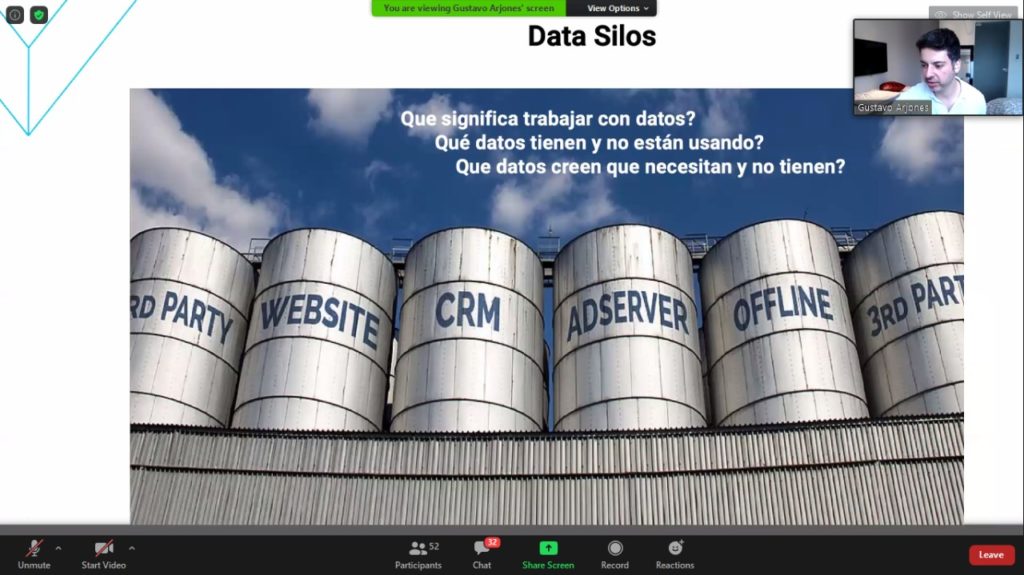
La propuesta de la charla giró en torno a responder una pregunta clave: ¿por qué los medios de comunicación tienen que aprender a usar datos? Porque justamente uno de los grandes desafíos que enfrentan es aprender a capturar datos, procesarlos y analizarlos. Solo con un mayor conocimiento de los usuarios y las audiencias, seguramente podrán encontrar mejores formas para monetizar esa información.

“Si cada vez más el dato es el núcleo del negocio, ¿cómo es que todavía nosotros, como parte del grupo de gestores de ese negocio, no lo podemos describir con la misma fluidez que describimos cómo publicar una nota o cómo hacer una investigación, o cómo vender una suscripción o una membresía?”, interpeló el experto a unos 50 editores y directivos periodísticos de todo el país que siguieron la charla a través de Zoom.
El objetivo de su clase fue que los participantes se llevaran conocimientos sobre el procesamiento de datos y de qué formas materializarlo. “Trabajar con datos no es un proyecto, es un cambio de paradigma. Tiene que ser parte del negocio. Y lo hacemos para pasar de ser compañías basadas en el instinto a ser compañías basadas en datos para tomar decisiones”, subrayó Arjones.
Antes de profundizar en Big Data, en herramientas de automatización de procesamiento de datos, en los tipos de datos que existen y cómo aplicarlos, Arjones hizo una introducción acerca de qué significan los datos y qué ganamos al generar una mentalidad orientada hacia ellos.
Una visión 360º del cliente para crear servicios y generar ingresos
Para iniciarse en el tema, lo primero que deberían hacer los medios, según el especialista, es “levantar información y empezar a crear una visión 360º del cliente”.
“Tener muchos más datos específicos de nuestros usuarios, lectores, de la gente que tiene una membresía o suscripción de nuestro medio, nos servirá para hacer un entrecruzamiento de su comportamiento. Eso nos daría mucho más valor al momento de monetizar esa persona”, explicó Arjones.
El entrecruzamiento de información se logra con herramientas tecnológicas. “Nos permiten ver de qué forma enfocar nuestros esfuerzos para conseguir una mejor eficiencia de las ventas”, señaló.
Toda la información que se captura sirve para alimentar el machine learning (aprendizaje automático), buscar patrones en los datos y generar nuevos servicios. “Gran parte del desafío que ustedes tienen es cómo generan nuevos servicios o funcionalidades, enriquecidos y personalizados, para que sus usuarios estén cada vez más contentos y se queden más tiempo dentro del medio. Y de esa manera, generar nuevas líneas de negocio que aumenten los ingresos”, precisó.
La pirámide de valor, clave para la eficiencia en el procesamiento de datos
Para que el procesamiento de la información sea eficiente, hay que hacer un manejo correcto de los datos. En ese sentido, Arjones hizo referencia a la pirámide de valor que se debe completar entera. Debe incluir Big Data, Machine Learning y Use Cases.
En la base de la pirámide se ubica Big Data o Data Engineering, que existe para almacenar y procesar la información de un medio. Es el llamado Data Lake. “Es un repositorio central a donde podemos alojar todos nuestros datos para hacer después los cruces de información. El gran potencial de esa información es el valor de cruzarla. Hay diferentes sistemas para hacer el entrecruzamiento. Si estamos preparando un producto, empezaremos a entender mejor al usuario porque ahí se verán varias facetas”, explicó Arjones.
Amazon, Google o Azure tienen sistemas de data lake. “Hablando con el equipo de tecnología de sus medios pueden decidir cuál tiene mejor sentido. Pero primero, si aún no lo hicieron, les sugiero llevar los datos a la nube para almacenar y procesar desde ahí la información”, aconsejó.

Una vez que el medio cuenta con los datos, se puede pasar a la etapa de Machine Learning. “Figura con distintos nombres: Machine Learning, Deep Learning o IA. Básicamente, son técnicas diferentes para llegar a lo mismo: hacer una predicción o reconocimiento de comportamientos”, graficó.
Todo esto tendrá sentido si la compañía lo hace por los Use Cases, es decir, los casos de negocio. “Es muy importante estar pensando en por qué yo estoy metiéndome con datos. No tiene que ser porque está de moda, sino porque es importante y realmente tengo un plan de explotar esos datos, monetizarlos, y crear un diferencial interesante”, puntualizó.
Arjones sostuvo que como profesionales, los editores y directivos tienen que involucrarse: “El mejor producto de datos va a ser creado cuando ustedes se sienten junto con los equipos de tecnología para crearlo. Hace 20 años tuvieron que aprender sobre web, ahora les toca aprender más sobre manejo de datos”.
Oportunidades para aplicar datos y ejemplos de herramientas de automatización
Cuando uno dispone de datos sobre el comportamiento de las audiencias, se pueden hacer clusters por afinidad. “Esa segmentación de los usuarios permitirá generar, por ejemplo, productos especializados para segmentos o audiencias de nicho”, dijo Arjones.
Los datos pueden aplicarse también para generar un push de contenidos que no tuvieron suficiente audiencia. “Con sistemas automáticos podría generar nuevas formas de publicitar cierta nota que no fue tan leía, lo que les ayudará a no tener que crear siempre contenidos nuevos”, remarcó.
Como ejemplo de oportunidad para aplicar datos mencionó a The Pudding, una publicación digital que explica ideas debatidas en la cultura con ensayos visuales. “Es una forma interesante de trabajar con datos. El uso de datos es clave para generar contenidos mucho más completos y relevantes, que generen un mayor engagement, distribución y tiempo de la gente asociada a ese contenido”, precisó Arjones.
También se pueden vender los patrones de consumo, para después crear nuevos materiales y vender membresías o suscripciones, o conectar contenidos desagregados, contando una historia más completa.
Una de las herramientas que mencionó Arjones, que ayudan a hacer esos links de forma automática, para mantener a los usuarios dentro del medio y seguir generando navegación, es Zorroa, compañía de análisis de activos digitales que se especializa en visual search.
La otra es Croma, que se ocupa de seguir los contenidos, los social media, y permite entender qué está en la lista de publicación de los medios, qué se está “empujando” y qué contenidos debería “empujar” el medio.
Y la tercera es Radar, una compañía que genera un sistema de IA para que los editores y los periodistas sean cada vez más eficientes. “Captura información de otros medios, chequea fuentes y hace resúmenes automáticos. Esto permite que el editor que está por editar un contenido o el periodista que está empezando a armar una nota, ya tenga todo el workflow más definido”, describió Arjones.
Los tipos de datos y sus atributos principales
Arjones explicó que se habla de dos tipos de datos. Por un lado, los “datos estructurados”. “Podría ser un dato que ponemos en una planilla de Excel, datos de CRM, de usuarios, de suscriptores a una newsletter”, ejemplificó.
Por otro lado, están los “datos no estructurados”. “Serían los contratos o las conversaciones social media. Es una información que carece de toda esa estructura que estábamos viendo antes, pero puede ser muy rica en información”, indicó.

Lo interesante al hablar de estos tipos de datos es qué pasa cuando se cruzan entre sí. “El cruce es superimportante”, remarcó.
Tras esa identificación, habló de las “5 V de Big Data”, es decir, los atributos de los datos. Son volumen, variedad, velocidad, veracidad y valor.
Sobre el volumen dijo que no tiene que ver con la cantidad, sino con la capacidad de guardar información por largos períodos de tiempo y que estén accesibles para consultas.
En relación a la variedad, señaló que la pluralidad de datos ayuda a tener una película más completa de los usuarios. “Pueden ser datos estructurados como CRM, de localización, de social media, call center, chatbots y IoT”, enumeró.
La velocidad es importante para la captura, el procesamiento y las respuestas en real time. Al respecto, Arjones enfatizó: “La temporalidad es superimportante. Es clave no llegar tarde, no perder esa ventanita de tiempo. El negocio define qué es el real time, porque ustedes tienen que observar cómo es la aplicación del dato para decir cuál es la velocidad que necesito para capturar y procesar esa información”.
La veracidad, en tanto, tiene que ver con preguntarnos si los datos que tengo son confiables y si son usables. Por último, hay que cuestionarse si los datos que capturamos tienen valor. “Yo asumo que si estamos capturando información, es porque estamos viendo de alguna forma un beneficio futuro para eso”, apuntó.
La importancia de armar equipos multidisciplinarios
Para que los medios en los que trabajan crezcan y sus proyectos de datos sean exitosos, Arjones les dijo a los participantes que deben “participar de todos los procesos de datos” de sus empresas.
“Tienen que tener equipos multidisciplinarios, ya que se necesitan del aporte de diferentes roles. Para eso, deben contar con Data Scientist, agentes de IT, de Desarrollo”, precisó.
“En ese equipo sería clave contar con un analytics translator. Es una persona que conoce sobre el negocio y sabe lo suficiente del lenguaje técnico, para poder ser un traductor de las necesidades del negocio hacia los equipos de tecnología”, les recomendó Arjones.
A priori, les recomendó probar una serie de herramientas que “fueron pensadas para personas de negocios que no tienen todos los conocimientos de programación, pero que necesitan hacer cosas que funcionen”. Forman parte del «movimiento low-code (poco código)» y «movimiento no-code (sin código)».
“Estas herramientas sirven para hacer experimentaciones con datos y crear flujos de datos distintos. Les puede ayudar a acelerar su día a día, principalmente a aquellos medios que no cuentan con un equipo dedicado al manejo de tecnologías o sí, pero el equipo dedicado ya está al 150 % de su capacidad”, amplió Arjones.
Les aconsejó hacer “una combinación de herramientas con API (Application Programming Interface)”. Como el sitio Makerpad, que tiene tutoriales de videos sobre herramientas que consideran low-code y no-code. Y Azure, que ofrece herramientas para identificar personas en una foto y detallar información de cada una.
Para finalizar este segmento, les compartió unas preguntas para que se hagan como gestores, que los ayude a ser más eficientes y a tomar decisiones más alineadas a los datos: ¿Puedo cuantificar cómo y por qué pierdo clientes? ¿Qué nos dicen los datos? ¿Tomo decisiones basadas en la intuición? ¿Hago experimentos para validar hipótesis basados en datos? ¿Se hace esa experimentación o simplemente estoy haciendo cosas sin KPI claros? ¿Promuevo la comunicación de la performance del negocio a través de KPI y no métricas aisladas?
Datos y negocio, una alianza para garantizar la supervivencia de productos
Antes de cerrar la clase, Arjones aprovechó los últimos minutos para exponer algunas de las cosas que no deberían hacer los medios con un proyecto de datos. “Hay mucho que aprender sobre las tecnologías, los datos y la conformación de equipos. Empecemos con proyectos más chicos, hagamos la experimentación y en función de los resultados, avanzamos con los proyectos”, les propuso Arjones.
En segunda instancia, les dijo que no asuman que la integración de datos será sencilla. “Si nuestro medio tiene muchas fuentes de datos, hay que integrar y generar ese data lake que genere el punto de información”, indicó. Mientras que aseguró que no hace falta aplicar Data Science, Machine Learning y IA de entrada: “Un buen cruce de información con un storytelling interesante mata cualquier IA”. Y destacó que deben experimentar. “Tiene que ser parte de nuestro ADN. Solo experimentando llegaré a algo más interesante o al mejor resultado posible”, planteó.
De acuerdo a sus observaciones, “cada vez más los productos basados en datos son los únicos que pueden sobrevivir”. Por lo que volvió a destacar la importancia de integrar los datos y el negocio: “Tener los datos desconectados genera una contingencia en el negocio. Podemos generar algo mucho más interesante a medida que lo trabajemos en conjunto”.



